In the most popular desktop operating system applications are installed using binaries which contains everything that app needs to run. This approach has many advantages: It’s easy, people just click on it, wait for it, and that’s it. But it also has its share of problems, binaries tend to be big, since they need to contain everything, multiple apps containing the same libraries install a new one every time, and there’s little cross library use beyond what Microsoft provides.
Because of its nature, there never was any need for a centralized system, because all binaries contained everything Apps needed, software was usually found on physical stores, and installed from physical media, the limitations on the speed of connections back then obviously didn’t allow for downloading all kind of apps, specially considering this packages contain every single file its needed, which obviously increases the size of this files.
As time went by, the internet became the main way in which people get their software, except for a few very specialized pieces, people have gotten used to fulfill their software needs by going to a search engine, writing what kind of app they want, opening different links to all kind of sites, and then download what seems to be best fitted. Of course this has many disadvantages, perhaps the most prominent disadvantage users of Windows face is downloading an insecure file, spyware, malware or viruses that compromise his computer and his data. Linux based operating systems chose a different path.
A little bit of history
At the beginning, there was the source. As Linux is and was an open sourced operating system, most users back then were developers supporting the cause, or curious advanced users, because of this, the way they used to install their application was by downloading the source code and compiling it. Beyond requiring knowledge about compilation, the biggest issue was something nicknamed Dependenciy Hell (Windows used to suffer a form of this hell too, it can still happen, but it’s a really rare occurrence: DLL Hell).
Since the idea was to avoid as much as possible diverging developers’ workforce, applications started sharing libraries, this meant that apps wouldn’t compile (wouldn’t run) unless the needed (shared) libraries were previously available on your system. Now picture this: MP3 Players may seem like a very simple piece of software, but they depend on a lot of libraries, like all the graphical tools it needs to draws the window on your computer screen (which may seem like an easy task, but this thing is telling your computers how to draw every pixel on your screen, and redrawing everything on real time each time you move that window), sound libraries, OS-level implementations, etc. Now say you want to install this MP3 Player, because it looks really cool, you download the source code, you try to compile it but then you get an error message saying Missing Dependencies (it was not nearly as clear, but for the sake of simplicity lets assume it was), meaning some of the needed libraries are not currently installed, so you checked the output and you see that your system is, thankfully, missing only one dependency: libqtgui4.
So you naively and happily go to download libqt4gui4′ source code then you go ahead and try to compile it, but oh, surprise! This dependency is also missing dependencies! And some of those are missing dependencies too! And this goes on and on, on top of that, you need to install the correct version of each dependency, even worse, it’s not always the latest version, so many times you were forced to hunt it.
Developers, tired of this problem as much as users were, started thinking how to solve this without duplication, without implementing a package that carried everything it needed because this means users will end up installing 10, 20 or 30 copies of the library. Red Hat was the first company to come with a partial solution, called Red Hat Package Manager, better known as RPM, and Debian came little after it with their Debian Package Manager, DPKG, with its packages’ format deb. This kind of package contain metadata with the description and dependencies. Then the package manager makes a database with everything installed on the system (with rpms or debs), and when you want to install a new one it checks if dependencies are met and if not it tells you exactly what is missing.
This helped, but was still a long shoot from being paradise. In fact, Red Hat’s partial solution also got its nickname: RPM Hell! Pages like rpm search are still up, actually, the rpm hell endured until not so long ago, despite implementing a similar system to Debian’s brilliant invention: Advanced Packaging Tool, better known as APT, the tool used by Netrunner.
The Advanced Packaging Tool
or How Linux was 10 years ahead of the rest
This is how Debian solved it: They came up with the idea of repositories, which are essentially storage locations where packages are found along an index file which specifies the packages that are there, the dependencies of each file, and where exactly they are. Now, this storage location can be anywhere, including the web. So say you pick a deb on the web, you try to install it, and this modern package manager looks on the web, finds the missing dependencies, and the missing dependencies of the missing dependencies, downloads and install them, and then proceeds to install your deb. This is what I call being bright.
But why should people keep going to the web and search on Google for their apps, if this package manager already knows where the packages are? So Debian made a centralized system, a big set repositories with most packages people need. This is way more secure than going to the web, because it’s curated, no viruses, no malware and no spyware. Also, if an update is pushed to the repository your apps can be updated automatically. Since this an open system, if a package is asked for, and have a maintainer it can get to the repositories. But, say you always want the bleeding edge stuff, or rare software, or closed source software, then you can add more repositories (as long as your trust the source) and have their dependencies and updates sorted out automatically too.
So let’s do a fact check: Everything can get automatically updated as soon as it hits the repositories, if you want an app, chances are that app is actually found on the default repositories, specially on Netrunner which includes a healthier selection of default repositories, healthier than most Linux distributions. It’s faster and securer. You can think of repositories as boxes where packages are thrown, and the package manager as the claw that get those packages for you.
Making APT easier: Front ends
Now, all up to this point, everything was done trough the console, everything was done by putting commands on a black window with a blinking cursor. Sure, it was faster, securer, more reliable, it updated automatically, but it still was too complicated for the average user. So the next step was developing a front end. A front end is the interface between the user input and the back end, in this case, the back end is APT, and there all kind of front ends, from CLIs (Command Line Interfaces) to GUIs (Graphical User Interfaces). Obviously the best way to connect a user with APT was by using a GUI.
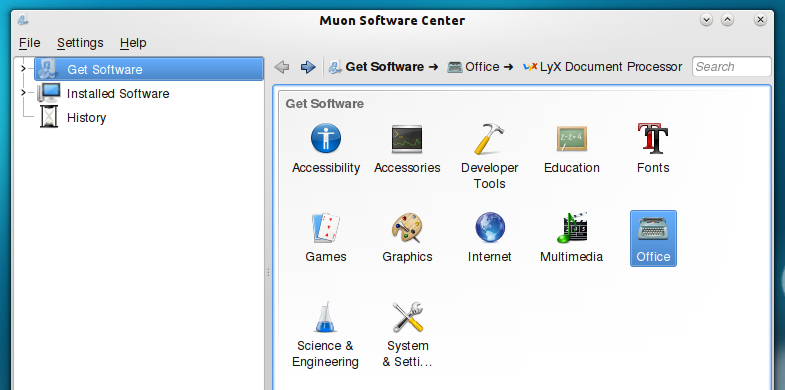
Front ends are really simple in principle, the places where the user clicks represent different commands, so for example, instead of writing sudo apt-get install lyx, which is apt’s command to install things, users can simply click on the desired thing (say Lyx) and then click install and once they do this their front end will tell the back end to run precisely that command. Front ends of APT are specially good at presenting information to users, for instance, instead of writing sudo apt-cache search lyx, they can simply click on the magnifier icon, or on the search space, and type, and get instant results as they type, instead of writing sudo apt-cache show lyx, and then reading its description as the output of a console, you simply click Lyx and read the same description paired with screenshots, front ends are a way to make things easier without giving up the features and more importantly is absolutely modular, this means that there can be as many different front ends as there are developers with different ideas. The following is an APT front end:
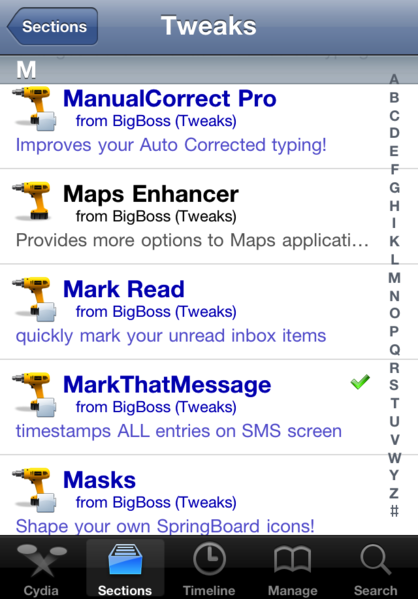
Wait, isn’t that an iPhone? Yes, it is. APT is such an advanced tool, as it names correctly implies, that has even been ported to iOS, to produce a similar store to Apple’s official App Store for homebrew developers who’s apps aren’t allowed by Apple’s restrictive rules. But think about it for a second, they used a 14 years old tool to recreate one of Apple’s strongest points, by now you should realize why Linux was so ahead of the rest: Apple first did it with the iPhone, and then with Mac OS X Leopard, Google followed with Android, and now even with Google Chrome, and Microsoft implemented it a little bit more than a year ago on Windows Phone 7, and will keep the trend with Windows 8. Yet, Linux has been doing it for more than a decade ago, several years ago Ubuntu introduced a more user-friendly interface, with apps’ descriptions, one click installs, auto-updates, secure, everything people cheer about this new stores.
If APT’s impressive features captured your attention, you may want to read our article Visual Guide: Muon, where we show how to use them more effectively, or the upcoming Linux Inside: Mastering APT, where we will present the back end itself, and how to solve some common errors users face.
[sharedaddy]



Pingback: Visual Guide: Muon | Netrunner Magazine