If you think this is some fresh new street lingo, and you feel outdated and outclassed, don’t. OCR stands for Optical Character Recognition, and YAGF stands for, uh, something. But it is a neat graphical interface for cuineform and tesseract tools, the latter of which we’ve tested in decent depth on Dedoimedo some time ago.
One of the big hurdles with tesseract was that it is a command-line only tool, and it comes with some rather strict requirements on the type of images it can use. Most people probably just want a simple utility that can scan and convert their documents and extract text. Cue in YAGF, and this little review. Let’s see what gives.
Setup & initial niggles
I tried the program in Xubuntu 15.04 Vivid (review coming soon!), and it’s available in the repositories. No biggie. The program comes with a three-pane interface. The leftmost will include your added images or files, both from the disk and scans. The middle pane shows an enlarged view of the selected image, where you can do some basic manipulation, like rotation, zoom and alike. Recognized text will show in the right column, which you can then copy, export or save in several formats.
My first attempt to load either a PNG or a TIFF file did not work well. YAGF would freeze indefinitely, and eventually crash, without any useful information on the problem. It took me some time browsing online forums to figure out the cause. As it turns out, in the settings, under Image Processing, you should uncheck the automatic crop option. After that, YAGF worked fine.
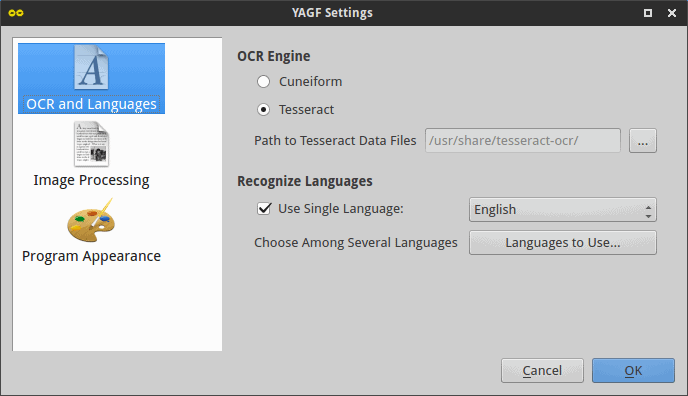
OCR hard at work
Like the last time, I used the control images from the original experiment, provided by Andreas at splitbrain.org. I started with the Justy black font on gray background. The initial view may be a little hard to read, and you will need to zoom in a little. Then, hit the fourth button from the left on the toolbar, and let YAGF do its magic. Depending on your processor speed, memory and the size and complexity of the image, this can take a while.
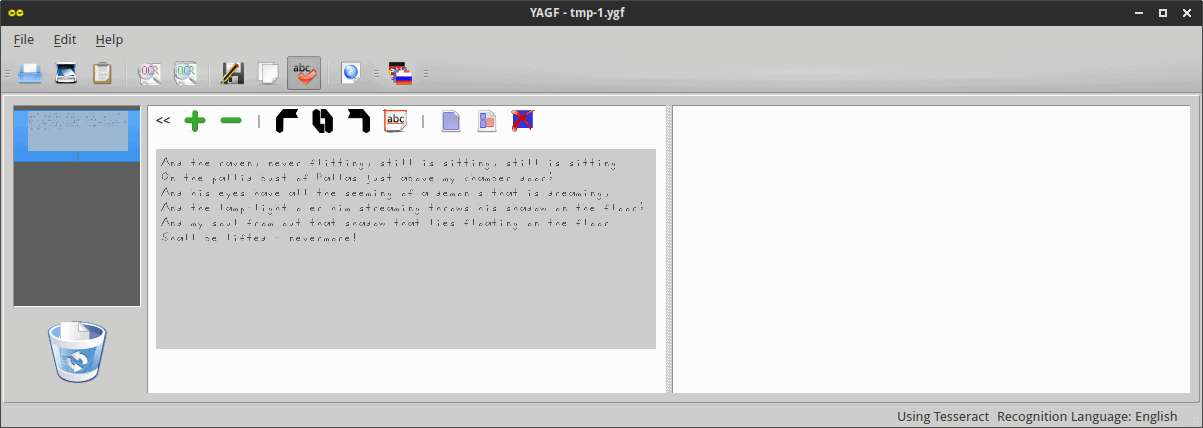
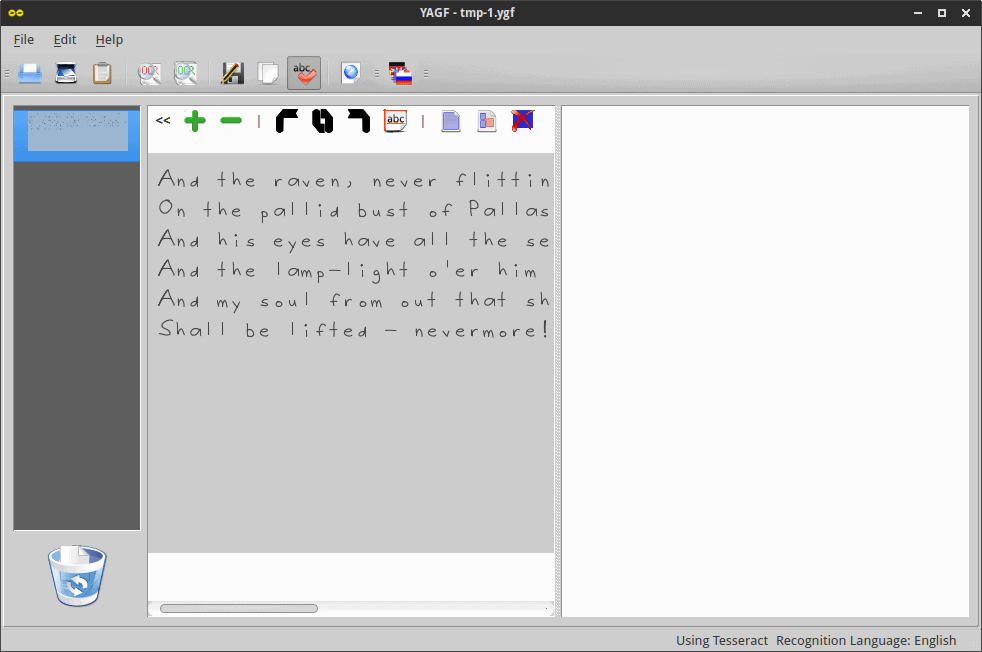
Four years since my review, wavy, curly fonts still pose a significant challenge for Tesseract. The rendered text is virtually unreadable, and it’s impossible to decipher what it’s mean to be. Perhaps using the learning mode and teaching tesseract could improve the results, but, with default settings, the first attempt wasn’t very impressive.
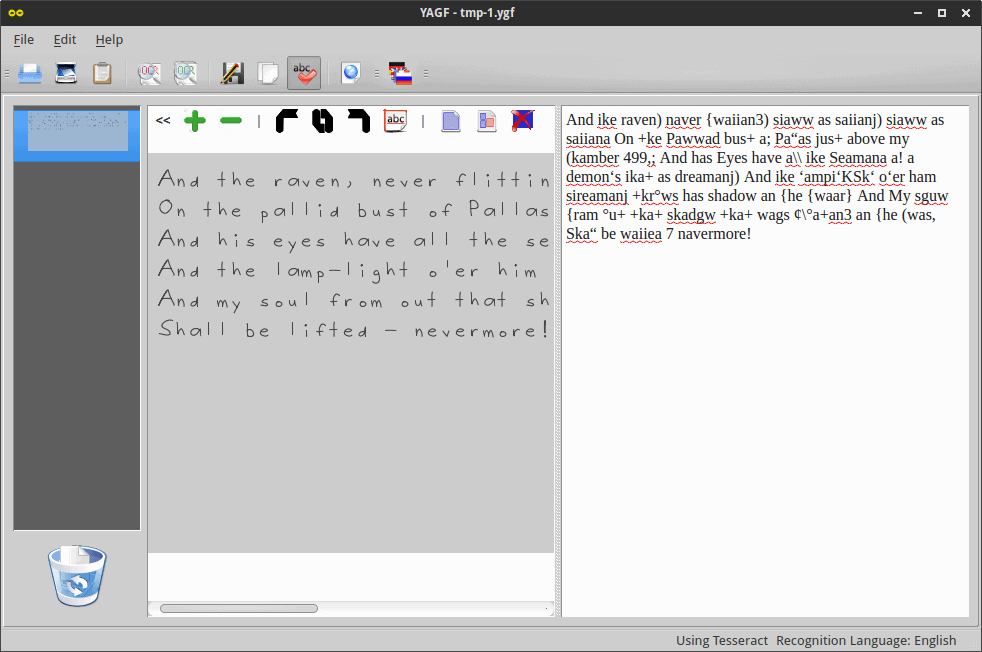
With the Courier font, black on white, the results are far more satisfactory. The OCR output is almost perfect. The rotated text did pose a bit of a challenge. Initially, YAGF would not render anything, and only after I let it auto-detect and rotate the image did it yield some results. Again, quite decent.
If you’re wondering or want to run your own tests and comparisons, here are the actual produced text files from the first and last conversion, namely Justy and Courier (rotated version):
And ike raven) naver {waiian3) siaww as saiianj) siaww as saiiana On +ke Pawwad bus+ a; Pa“as jus+ above my (kamber 499,; And has Eyes have a\\ ike Seamana a! a demon‘s ika+ as dreamanj) And ike ‘ampi‘KSk‘ o‘er ham sireamanj +kr°ws has shadow an {he {waar} And My sguw {ram °u+ +ka+ skadgw +ka+ wags ¢\°a+an3 an {he (was, Ska“ be waiiea 7 navermore!
.4; Liltting, still is sitting, still is sitting -ua pailid bust 0f Pallas just above my chamber door; And his eyes have all the seeming of a demon’s that is dreaming, And the lampalight o'er him streaming throws his shadow on the flooz: And my soul from out that shadow that lies floating on the floor Shall be lifted v nevermorel
Working with PDF
An interesting new feature that YAGF offers is the ability to work with PDF files. In some cases, the files might be protected, and you might not have the option to copy text, or there might be useful information embedded inside images included in the PDF documents. You can try online conversion tools, but perhaps YAGF can offer similar, if not better results. As a test file, I grabbed my own Linux kernel crash book, which comes with an interesting assortment of formatted text, plain-text paragraphs, as well as screenshots.
YAGF handled the 182-page document well, so this is an encouraging sign, because it means it can probably work with large data sets. You can still convert pages one by one, or use a bulk conversion tool, the fifth from the left, but will discuss that soon.
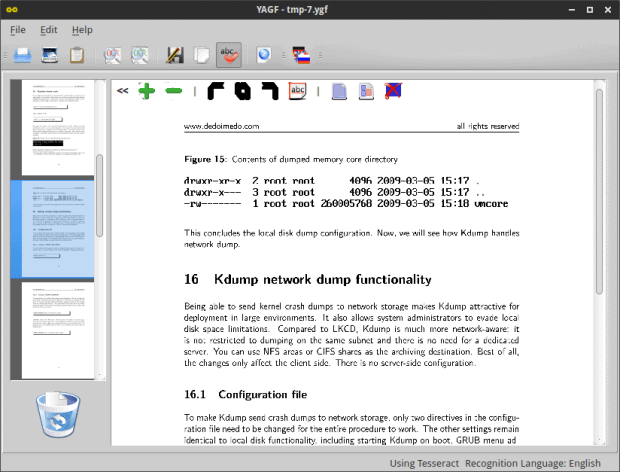
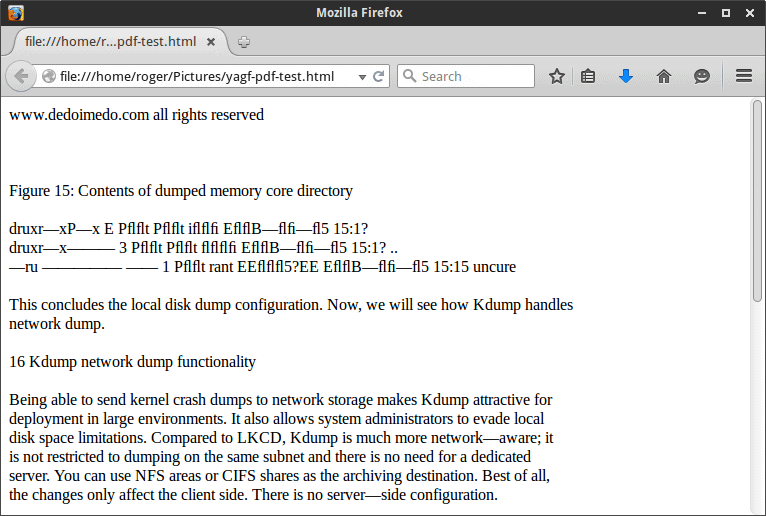
The output is, well, not as good as one might hope for. Plain text, which can just be copied and pasted, is fine. But YAGF did not handle code/command blocks and images that well. I can understand that images might pose some problem, but text boxes really shouldn’t be a challenge.
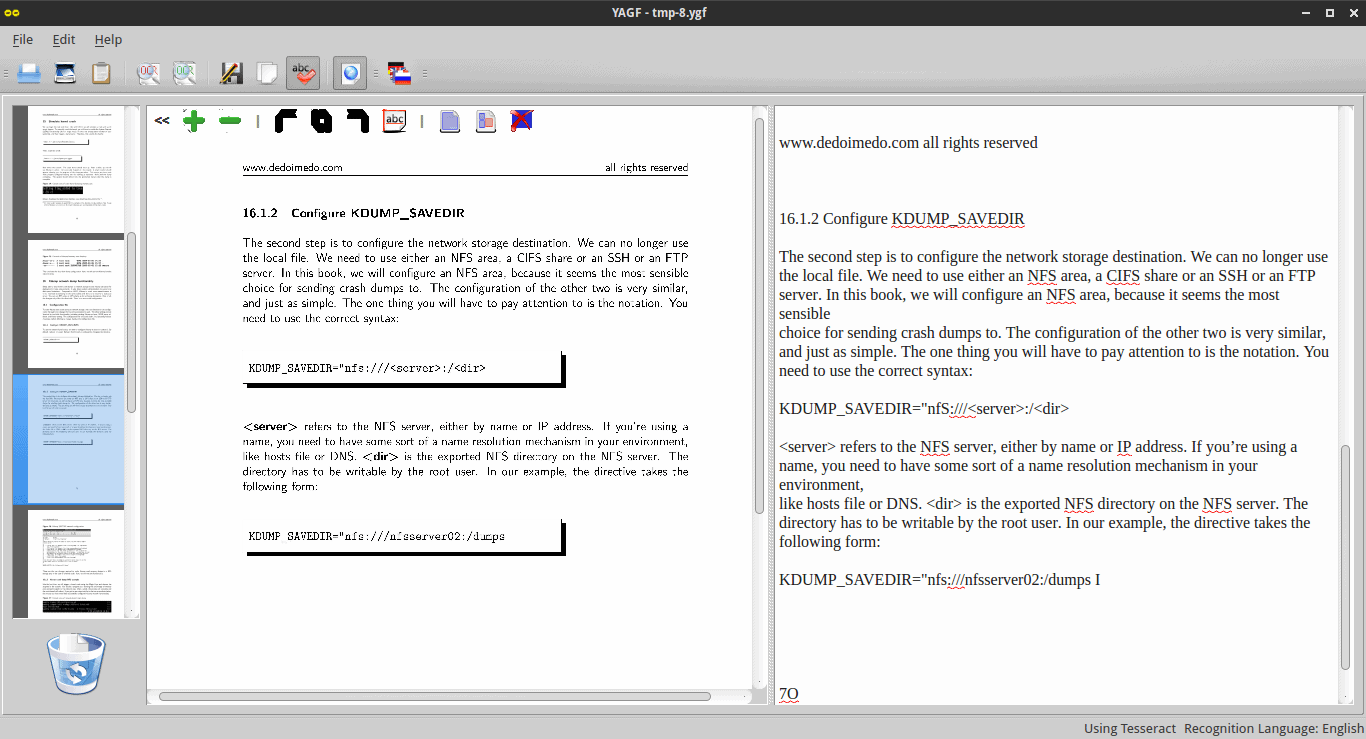
Other things
In general, YAGF worked well, once I sorted the initial problems. While it’s thinking, it may appear as if it’s frozen and unresponsive, but overall, the program works decently, considering the fact it needs to do some heavy uplifting in the background. Last but not the least, using the bulk conversion option resulted in a cryptic error. I am not even sure why selecting all pages would make tesseract break, or why it’d display such a weird message. At no point was I using any BMP files.
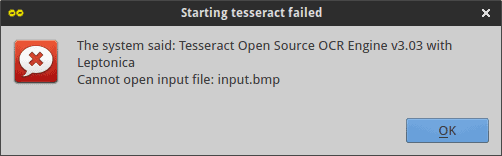
Conclusion
YAGF is a useful little tool, which can make your OCR adventure that much easier and simpler to manage. The interface is intuitive, the feature set is good and practical, and the tool works well, most of the time. The biggest underlying challenge is for the tesseract engine to cope with different fonts and background colors.
Still there were some small problems, like the initial crash and the multi-page select bug. This is a good starting point, but YAGF could do more. I think the inclusion of additional engines would be useful, focus on additional languages, and the ability to train the OCR software from within the interface. Now, it’s been four years since I’ve last played with this kind of technology, and there does not seem to have been any great leap forward, which is why I’m cautiously pessimistic, but perhaps YAGF will surprise and deliver an excellent, smooth experience in its upcoming releases, its vague acronym notwithstanding. We shall, indeed, keep a proverbial eye on its optical capabilities.
Cheers.
[sharedaddy]



I used tesseract after pdf->tif conversion with imagemagick or gsview on some lab notebooks. The resolUtion of the tiff had a dramatic effect on the quality of the output. The more intriguing possibility is to train it to recognize handwritten text or customize it in different fonts etc.